总的来说,视觉研究可以分以下几个部分:
首先是基础理论,例如统计学习、优化方法、深度学习技术等;
接下来考虑底层视觉,如超分辨、图象增强、去模糊、去噪声、去反光等等;
再到中高层的语义理解,包括场景理解、物体分类与检测、人脸、手势、人体姿态的识别、分割和分组等等。
除了二维视觉以外,三维视觉的研究也有着极其重要的地位,包括三维重建、点云处理和分析、景深感知分析等等。
同时,在人工智能时代,数据生成的方法研究也是一项有价值的任务。在一些工业场景中,视觉计算借助海量算力来做一些神经网络架构搜索的研究,以及模型压缩与量化。
最后是视觉与其他模态的结合,比如视觉与语言的结合,视觉与图形学结合,这都是计算机视觉领域的一些基础性的研究课题。
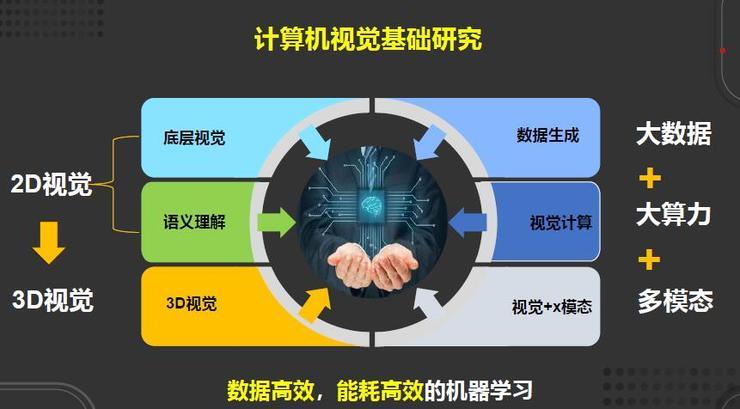
华为的基础研究就是围绕底层视觉、语义理解、三维视觉、数据生成、视觉计算、视觉+多模态等方面,构建数据高效、能耗高效的机器学习能力。

华为对底层视觉的研究涉及诸多方面,这些技术有着广泛应用场景,比如,为了提升手机端的图片质量,我们对照片进行超分辨和去噪处理,并提出了一系列有针对性的算法以面对从Raw域到sRGB域去噪,来提高照片的清晰度。

在语义理解方面,由于图像视频包括丰富的语义信息,如何有效理解并分析它们是一项富有挑战性的课题。以下举几个例子来说明:
挑战之一:同一内容的视觉特征的差异性。比如说拥抱这个动作,虽然是内容相同,但视觉表征可能非常不同,我们称其为类内差异性。
挑战之二:不同内容的视觉特征十分相似,我们称其为类间相似性。比如上图的两个男子,从图像上看,他们的视觉特征非常相似。但是放到场景中,一个是在排队,一个是在对话,这直观地解释了不同类间具有很高的类间相似性。
挑战之三:如何区分正常事件与异常事件。比如一群人在晨跑和一群人在斗殴,这往往会造成边界模糊。

对于3D视觉而言,虽然三维数据比二维数据携带着更丰富的信息,但与之而来的是诸多挑战。
比如在医学领域,获取具有精准标注的医疗数据,往往需要专家的协助,这是困难并且昂贵的;同时,因为一些医疗影像通常是在一些很细微的地方有差异,所以区分正常样本和异常样本的难度非常大;此外,视频数据也存在大量的冗余,如何去除冗余并提取有效信息也很具挑战性。
最后,准确检测和追踪物体也极具挑战并值得进一步探索。
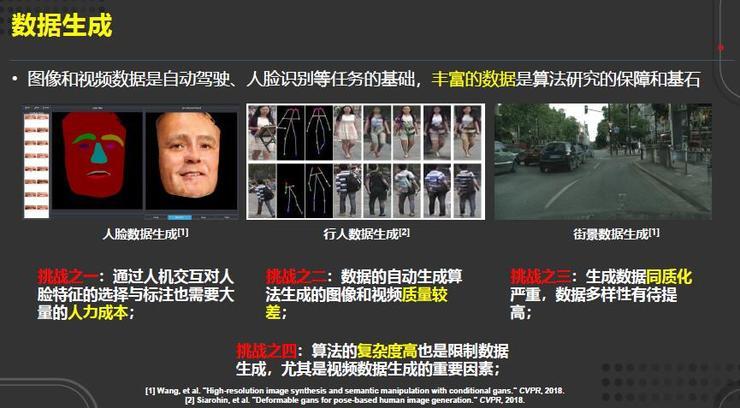
数据生成同样是一个热门研究方向。我们认为数据是视觉算法研究的保障和基石,在深度学习时代,大多数场景数据的收集越来越昂贵,所以数据生成具有直接的应用价值。
比如在安防企业中基于姿态的行人数据生成;在无人驾驶中街景数据的生成以及人脸数据的生成等。但目前该领域仍存在一些挑战:
挑战之一:通过人机交互对人脸特征的选择与标注需要大量的人力成本;
挑战之二:如何生成高质量的图像以及视频数据仍是巨大挑战;
挑战之三:生成数据同质化严重,数据多样性有待提高;
挑战之四:算法复杂度也制约着数据生成的性能,特别是视频数据生成这类对算力有着较高要求的任务。
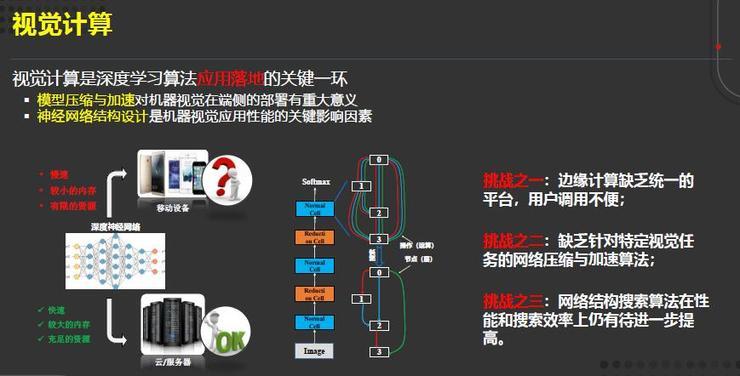
下一个基础研究是视觉计算,我们认为视觉计算是深度学习算法应用落地的关键一环。
它主要集中在两个方面:一个是模型的压缩与加速,这对机器视觉在端侧的部署具有重大的意义;另一个就是神经网络架构设计。
但是视觉计算目前仍然面临一些挑战。第一,边缘计算缺乏统一的平台,用户调用不便;第二,缺乏针对其它特定视觉任务的网络压缩与加速的算法;第三,网络结构搜索在性能和搜索的效率上都有待进一步提高。

最后一个研究领域是视觉与多模态。真实世界的数据是多模态的,比如在自动驾驶中,除了摄像头的输入,还有激光雷达的点云数据;在图片、视频的描述中,从图片、视频到文字的映射等。
它们存在的挑战,包括数据融合的问题、数据对齐的问题、数据异质性的问题、主观性和不确定性的问题、还有协作方面的问题,都有待研究。
以上是华为计算机视觉基础研究的一些方向,下面介绍一下我们从这些基础研究中,进一步提出的华为视觉研究计划。

我们认为计算机视觉实际上面临三大挑战:从数据到模型、到知识。 从数据来讲,举个例子,每分钟上传到YouTube的视频数据已经超过500小时,如何从这些海量的数据中挖掘有用的信息,这是第一个挑战。
从模型来讲,人类能够识别的物体类别已经超过2万类,计算机如何借助于深度神经网络来构建识别高效的视觉识别模型,这是第二个挑战。
从知识来讲,在计算机视觉里面如何表达并存储知识,这是第三个挑战。
因此我们提出的第一个研究方向:如何从海量的数据中挖掘有效的信息?有两个主要应用场景,一是如何利用生成数据训练模型;第二是如何对齐不同模态的数据。

深度学习主要是监督学习的范式,需要大量人工标注的数据,而人工标注的成本越来越高,比如无人驾驶,数据标注成本可能成百上千万,因此华为也花了很大的人力物力来研究数据生成技术。
我们把数据生成技术主要分为三类:第一类是数据扩增;第二类是利用生成对抗网络GAN来合成更多的数据;第三种方法是利用计算机图形学技术来生成虚拟场景,从而生成我们所需要的虚拟数据。
在这三方面,华为在ICLR20、CVPR2018和CVPR2019都有一些相关论文发表,数据生成主要应用的领域在智慧城市、智能驾驶方面。

在这里,介绍一个我们最新的工作。我们提出知识蒸馏与自动数据扩增结合的方法,在不使用额外数据的情况下,可以达到业界领先精度:在ImageNet-1000 Top-1准确率为85.8%。之 前几年都是谷歌最强,它在ImageNet-1000上最高精度是85.5%。

数据的第二方面是多模态学习。例如无人驾驶有图像、GPS、激光雷达信息。相对于单模态,多模态具有天然的互补性,因此是场景理解的主要手段。
当然也面临很多挑战,比如多模态的信息表示、融合、对齐、协同学习等等。我们认为多模态学习是未来机器视觉的主流方式,在自动驾驶、智能多媒体方面有着广泛应用前景。
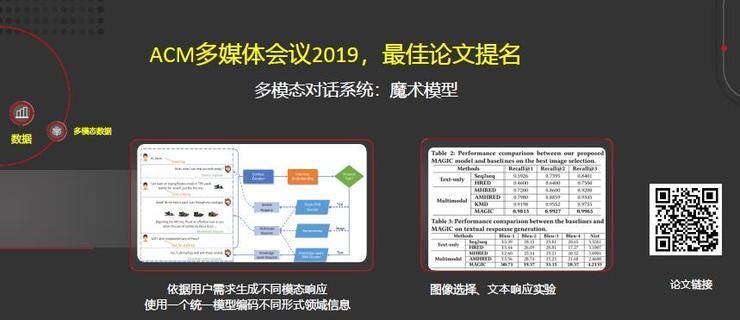
在多模态学习方面,介绍一个我们在2019年的ACM多媒体会议上获得最佳论文提名的工作,该工作主要是面对电商(服装)设计了一个人机对话系统。
具体而言,系统会依据用户需求生成不同的模态响应,使用一个统一模型以编码不同形式领域信息。最后在图像选择、文本响应都取得了很好的结果,右边的二维码是相关论文的链接。
第二个研究方向是:怎样设计高效的视觉识别模型?同样有两个应用场景,第一个是在深度学习时代,如何设计神经网络模型。第二是如何加速神经网络的计算。
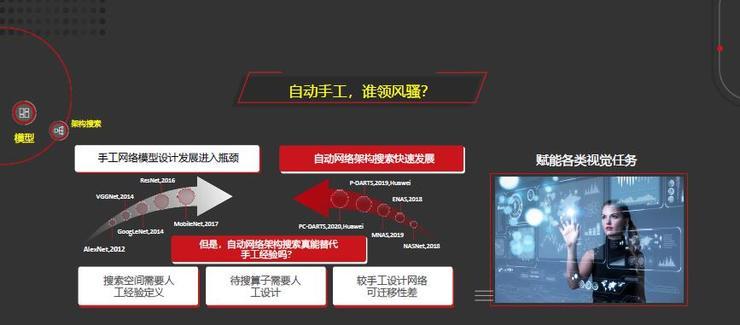
在神经网络设计方面有很多优秀的模型诞生,从2012年的AlexNet到VGGNet、GoogleNet、MobileNet,然而,手工网络模型设计进入瓶颈期。
2018年以来,自动网络架构搜索进入快速发展的阶段,包括今年华为的PC-DARTS在业界都取得了很好的效果。但是自动网络架构搜索真能替代手工经验吗?
主要面临以下几个挑战:第一是搜索空间需要人工经验定义;第二是待搜的算子也是人工设计的;第三是它相比手工设计的网络可迁移性比较差,抗攻击能力也比较差。

在这里介绍一下我们在ICLR2020提出的一个目前业界搜索速度最快的自动网络架构搜索技术PC-DARTS,它主要包含两个思想:一是采用局部连接的思想,随机地选择1/K的通道进行连接,可以解决冗余的问题;另一个是提出了边正则化的思想以保证网络稳定。
图片展示了这是Darts系列方法首次在ImageNet上完成的搜索,相较于之前的模型,搜索的效果更好,速度更快。右边二维码是相关论文链接。
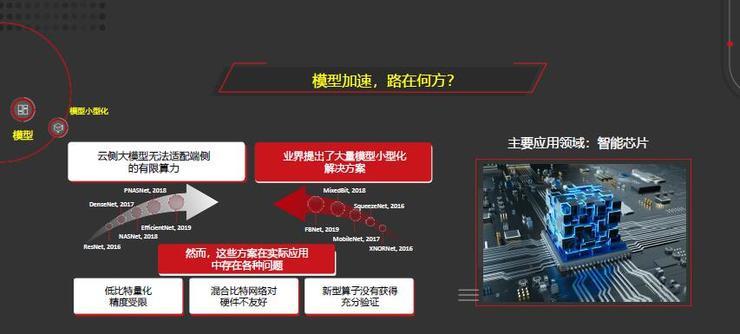
模型的另外一个研究方向是模型加速以及小型化。
对于早期的ResNet、DenseNet到最新的EfficientNet,由于云侧大模型无法适配端侧的有限算力,所以自2016年以来,业界提出了众多模型小型化的解决方案。
然而这些方法在实际应用中存在各种问题。比如,低比特量化精度受限;在实现的时候,如果用混合比特来表示响应和权重,这种混合比特的网络实现对硬件并不友好;此外,新型的算子也并没有得到一些充分的验证。

在CVPR2020,我们作了一个口头报告。该报告介绍了一个新型算子加速卷积网络,该算子的核心思想是在CNN中采用加法计算替代乘法运算。
从原理上讲,我们是用曼哈顿距离取代夹角距离。该方法用加法代替乘法运算,同时用8比特的整数计算,对硬件实现更加友好,功耗更低。
在ImageNet数据集上的结果表明,加法网络达到了基本媲美乘法网络的效果。虽然精度大概损失1%到2%,但其在功耗上具有显著优势。此外,二维码展示了开源代码以及论文链接。
第三个研究方向是通用智能,我们称其为知识抽取。可简要概括为两个场景,第一个是如何定义通用的视觉模型,打造我们的视觉预训练模型;第二是如何通过虚拟环境来学习、表达和存储知识。

我们的目标是构建一个通用视觉模型,类似于自然语言处理领域存在的预训练模型BERT、GPT-3,可以为下游的任务提供高效的初始化,满足系统所需要的泛化性和鲁棒性。
就监督学习和强化学习而言,监督学习需要海量的样本,模型无法泛化到不同的任务;而强化学习需要海量的试错,同样缺少可重复性、可复用性以及系统需要的鲁棒性。
虽然强化学习在一些游戏中,例如围棋、星际争霸等取得很好的效果,但是在一些简单的任务比如搭积木,效果就比较差。所以我们认为要学会推理预测,才能实现从视觉感知到认知。
从当下研究主流来看,自监督学习是成为常识学习的必经之路,但是目前的自监督学习缺乏有效的预训练任务,其在视觉领域的应用还不成熟。
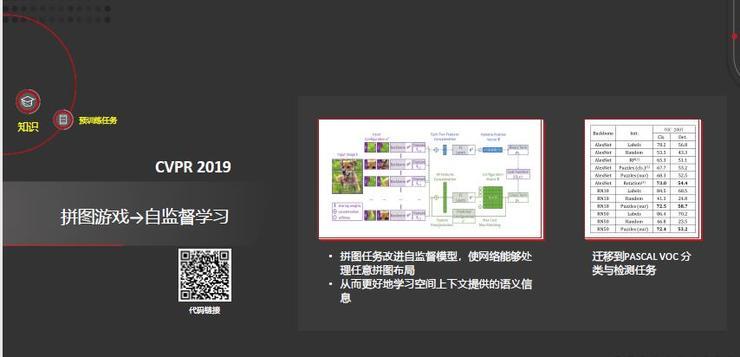
上图展示了我们在CVPR2019通过自监督学习来学习完成拼图游戏。具体而言,拼图游戏把一个图像分成3×3的9个小块,再把它的位置随机打乱,通过自监督学习来恢复图像原始的构成。
该任务能改进自监督学习性能,使网络能够处理任意拼图布局,从而更好地学习空间上下文提供的语义信息。我们把它在ImageNet上学习的结果迁移到别的地方,同样也取得了很好的结果。左下角二维码是我们的开源代码链接。
最后一个研究方向是构造虚拟场景来学习常识?因为深度学习需要大量的数据标注,这存在诸多问题:首先是标注成本特别高;其次是数据标注存在一个致命的问题,即知识表达不准确。